Enterprise technology leaders face a mandate that sounds contradictory but is entirely non-negotiable: ship faster while breaking nothing. Development teams are drowning in cognitive load. Operations teams are buried in ticket queues. And reliability too often becomes an afterthought that only surfaces when something has already gone wrong.
The market pressure is real. According to McKinsey, technology-driven companies grow revenue at twice the rate of their peers. Yet the average enterprise still takes weeks to move a code change from commit to production, and most incident response remains manual, reactive, and expensive.
The answer is not a single tool or a single hire. It is the strategic convergence of three complementary disciplines: DevOps, Site Reliability Engineering (SRE), and Platform Engineering. Organizations that integrate all three into a coherent operational model are consistently outperforming those that treat them as separate initiatives — in deployment frequency, system uptime, incident recovery times, and ultimately, revenue.
This guide is designed to give engineering leaders, architects, and practitioners a complete, practical reference for understanding, implementing, and scaling that convergence.
- Defining the Three Disciplines
- How DevOps, SRE, and Platform Engineering Work Together
- Key Concepts Every Engineering Leader Should Know
- Team Topologies and Org Design
- Tooling Landscape
- The Role of AI in Modern Operations
- Real-World Case Studies
- Common Anti-Patterns to Avoid
- Build vs. Buy: IDP Decisions
- Conclusion
- Related Resources
Defining the Three Disciplines
What Is DevOps?
DevOps is a cultural and organizational philosophy that unifies software development (Dev) and IT operations (Ops) around shared goals, shared accountability, and shared tooling. Rather than treating development and operations as sequential handoffs — build it, throw it over the wall, let ops run it — DevOps organizations embed operational thinking into the development process from day one.
Origins: The term gained mainstream traction around 2009, following Patrick Debois’ first DevOpsDays conference in Ghent, Belgium, and was accelerated by publications like The Phoenix Project and the annual DORA State of DevOps Report.
Core principles:
- Continuous Integration and Continuous Delivery (CI/CD)
- Shared ownership of production systems
- Automation of repetitive operational tasks
- Fast feedback loops from production to development
- Blameless post-incident culture
By the numbers: According to DORA research, high-performing DevOps organizations deploy code 208 times more frequently than low performers, have 2,604 times faster lead times for changes, and restore service 6,570 times faster after incidents.
DevOps is the philosophy. It describes what a high-performing engineering organization should value and how teams should collaborate. SRE and Platform Engineering are largely about how to implement that philosophy at scale.
What Is Site Reliability Engineering (SRE)?
SRE was invented at Google around 2003 by Ben Treynor Sloss, who famously defined it as “what happens when you ask a software engineer to design an operations function.” The core insight: if reliability problems are ultimately software problems, then the best people to solve them are software engineers — and the best solutions are software solutions.
SRE takes the cultural ideals of DevOps and gives them a prescriptive, engineering-driven implementation. SRE teams write code to manage systems, automate toil, define reliability targets mathematically, and use data to make trade-off decisions between speed and stability.
Core SRE practices:
- Defining Service Level Objectives (SLOs) and Service Level Indicators (SLIs) to quantify reliability
- Using error budgets to govern the pace of feature releases
- Eliminating toil — manual, repetitive, automatable work — as a primary engineering goal
- Conducting blameless post-mortems to extract systemic learning from incidents
- Building and maintaining runbooks and automated incident response playbooks
The SRE vs. DevOps distinction: DevOps is a philosophy applicable across the entire organization. SRE is a specific job function and implementation methodology, most commonly applied to teams responsible for keeping production systems reliable. Many enterprises use SRE as the operational implementation layer of their broader DevOps strategy.
Business impact: Enterprises with mature SRE functions report an average 15% increase in system uptime and a 40% reduction in incident response times. AI-integrated SRE teams achieve a 33% reduction in Mean Time to Recovery (MTTR) compared to traditional implementations.
What Is Platform Engineering?
Platform Engineering is the discipline of building and maintaining an Internal Developer Platform (IDP) — a self-service layer that abstracts infrastructure complexity and gives application developers a curated set of tools, environments, and workflows they can use without needing deep infrastructure expertise.
If SRE focuses on reliability and DevOps focuses on delivery velocity, Platform Engineering focuses on developer experience. Its core thesis is that developers produce better software faster when they don’t have to think about infrastructure, compliance, security configuration, or deployment pipelines — and that the best way to achieve this is to treat the platform itself as a product, with developers as its customers.
Core Platform Engineering concepts:
- Internal Developer Platforms (IDPs): A unified portal and toolset that gives developers self-service access to environments, pipelines, monitoring, and deployment
- Golden Paths: Pre-approved, fully automated routes to production that have security, compliance, and observability baked in by default
- Developer portals: Tools like Backstage provide a single pane of glass for service catalogs, documentation, and developer workflows
- Platform as Product: Platform teams operate with product management discipline — roadmaps, user research, feedback loops, and measurable adoption metrics
Why it matters now: Gartner predicts that by 2026, 80% of large software engineering organizations will establish platform engineering teams as internal providers of reusable services, components, and tools for application delivery — up from 45% in 2022. The driver is cognitive load. As cloud-native architectures have grown more complex — Kubernetes, microservices, service meshes, multiple cloud providers — the burden on application developers has become unsustainable. Platform Engineering solves this by hiding that complexity behind well-designed self-service interfaces.
Business impact: Organizations with mature Internal Developer Platforms report 40% faster onboarding for new engineers, significant reductions in environment provisioning time (from days to minutes), and measurably higher developer satisfaction scores.
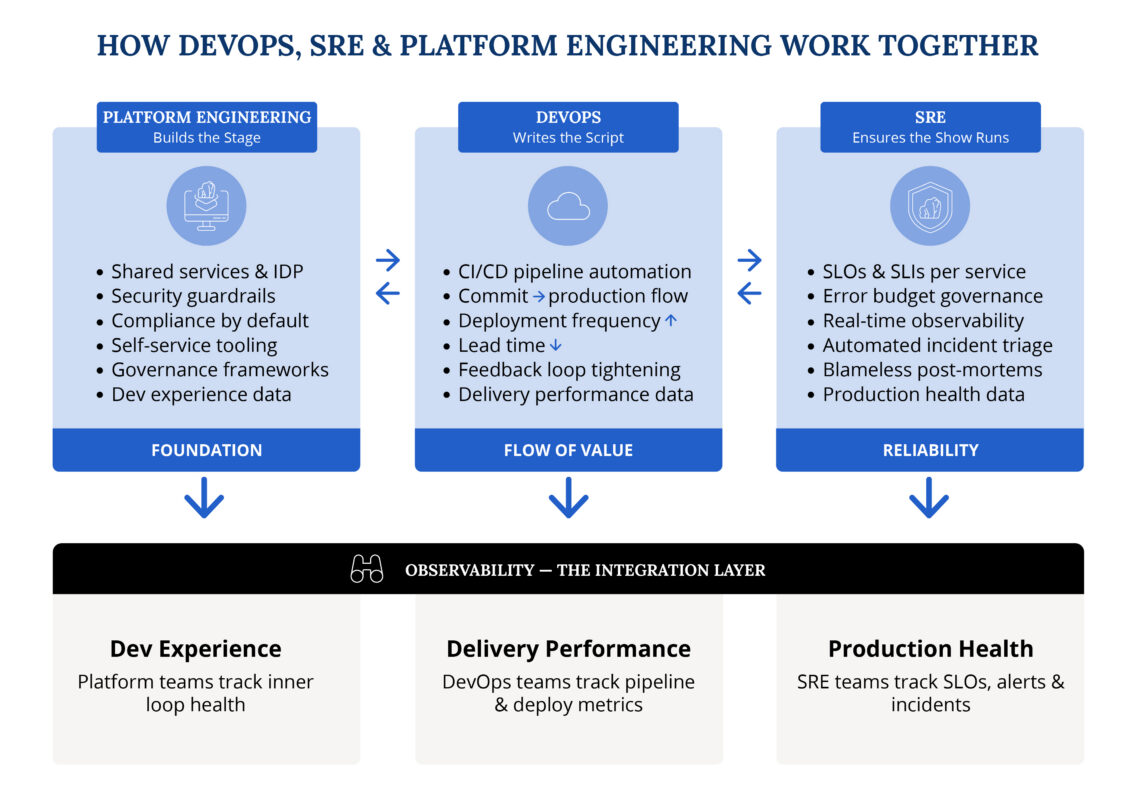
How DevOps, SRE, and Platform Engineering Work Together
A useful mental model: Platform Engineering builds the stage. DevOps writes the script for delivery. SRE ensures the show runs without interruption.
Implemented in isolation, each discipline creates local optimization but not global efficiency. A DevOps team with great pipelines but no reliable platform still spends half its time fighting infrastructure. An SRE team with excellent observability but no shared delivery standards still fights fires caused by inconsistent deployments. A Platform Engineering team with a beautiful IDP but no reliability culture still watches production incidents go unresolved for hours.
In a mature, integrated model, the three disciplines reinforce each other:
Platform Engineering provides the foundation. Shared services, governance frameworks, security policies, and compliance guardrails are encapsulated in self-service tooling. Product teams spin up fully compliant resources by default. Security is a property of the platform, not a gate at the end of the pipeline.
DevOps CI/CD pipelines automate the flow of value. Code moves from commit to production quickly and safely because governance is already baked into the platform it runs on. Deployment frequency increases. Lead time decreases. Feedback loops tighten.
SRE operates across the entire landscape. SLOs and SLIs define what “reliable” means for each service. Observability tooling provides real-time visibility across the stack. Error budgets govern when teams can ship features and when they need to focus on stability. When incidents occur, automated triage and blameless post-mortems accelerate recovery and prevent recurrence.The integration point between all three is observability — the shared telemetry layer that gives Platform teams data about developer experience, DevOps teams data about delivery performance, and SRE teams data about production health.
Key Concepts Every Engineering Leader Should Know
DORA Metrics
The DevOps Research and Assessment (DORA) metrics are the industry-standard framework for measuring software delivery performance. There are four core metrics:
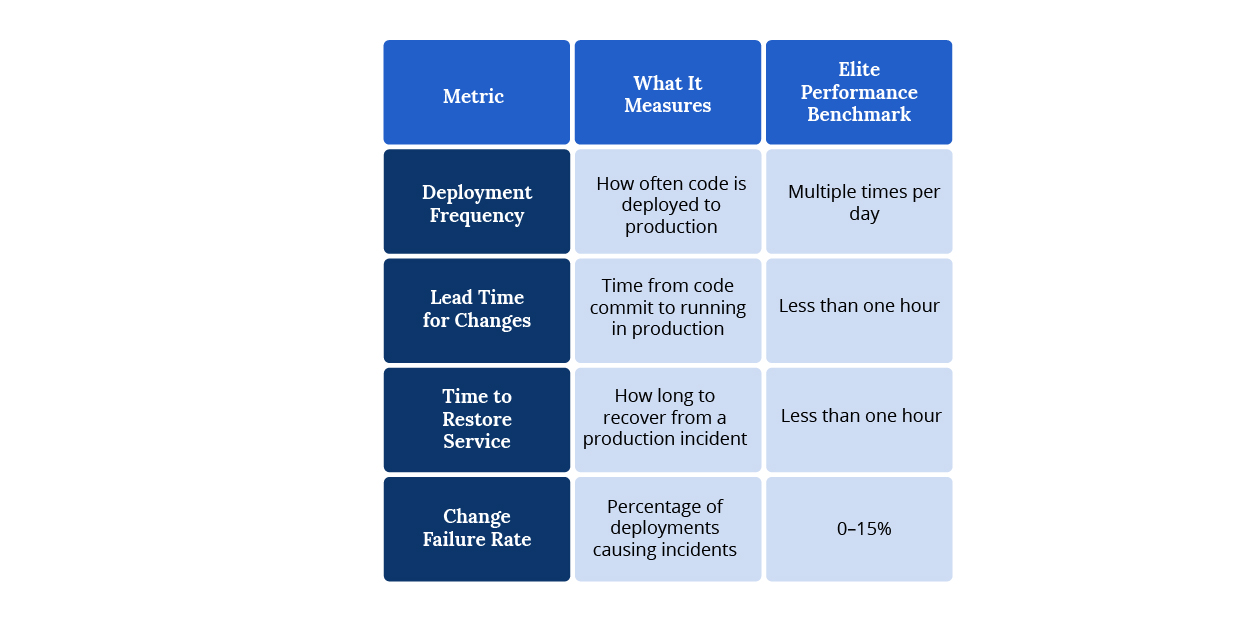
DORA metrics are the starting point for any DevOps, SRE, or Platform Engineering initiative. They establish a performance baseline, identify where the biggest bottlenecks exist, and provide the data needed to demonstrate ROI to business stakeholders.
Service Level Objectives, Indicators, and Agreements
These three terms form the backbone of SRE practice:
Service Level Indicators (SLIs) are the specific metrics used to measure the reliability of a service — things like request latency, error rate, availability percentage, and throughput.
Service Level Objectives (SLOs) are the internal reliability targets set for those indicators. For example: “99.9% of API requests will complete in under 200ms.” SLOs are the contract between an SRE team and the product teams they support.
Service Level Agreements (SLAs) are the external, contractual commitments made to customers, typically with financial penalties for breach. SLAs should always be slightly less ambitious than your internal SLOs, to give you a buffer.
Getting SLOs right is harder than it sounds. Too aggressive, and you’ll freeze all feature work chasing perfect reliability. Too lenient, and customer experience degrades. The discipline is in finding the target that aligns reliability investment with actual user expectations.
Error Budgets
An error budget is the amount of unreliability you are allowed before breaching your SLO. If your SLO is 99.9% availability, your error budget is 0.1% — roughly 8.7 hours of downtime per year.
Error budgets are one of SRE’s most powerful concepts because they transform reliability from a vague aspiration into a quantified resource that can be spent, conserved, and managed. When the error budget is healthy, teams have permission to deploy frequently and take risks. When it’s depleted, the conversation about whether to slow down feature work becomes data-driven rather than political.
Golden Paths
A Golden Path is a Platform Engineering concept: a pre-built, fully automated, opinionated route to production that has been designed and approved by the platform team. It includes everything a development team needs — source control, CI/CD pipeline, security scanning, infrastructure provisioning, monitoring, and deployment — packaged into a self-service template.
The key word is “opinionated.” Golden Paths don’t give developers infinite flexibility; they give developers a curated path that is fast, safe, and compliant by default. Teams can deviate from the Golden Path, but they accept responsibility for anything outside it. This creates a healthy balance between standardization and autonomy.
Infrastructure as Code (IaC)
Infrastructure as Code is the practice of managing and provisioning infrastructure through machine-readable configuration files rather than manual processes or interactive configuration tools. Tools like Terraform, Pulumi, and AWS CDK allow teams to define servers, networks, databases, and cloud resources in version-controlled code.
IaC is foundational to both Platform Engineering and SRE. It enables reproducible environments, eliminates configuration drift, makes infrastructure auditable, and allows platform teams to encode compliance and security requirements directly into reusable modules.
Observability
Observability is the ability to understand the internal state of a system from its external outputs. A highly observable system lets engineers answer the question “what is happening, and why?” without needing to deploy new instrumentation.
Modern observability is built on three pillars:
- Logs: Timestamped records of discrete events
- Metrics: Numeric measurements of system behavior over time
- Traces: Records of a request’s path through distributed services
Tools like Datadog, Dynatrace, Honeycomb, Grafana, and OpenTelemetry form the core of most enterprise observability stacks. Observability is the connective tissue between SRE (which defines reliability targets), Platform Engineering (which instruments the platform), and DevOps (which uses telemetry to optimize delivery pipelines).
Team Topologies and Org Design
How you structure teams matters as much as what tools they use. Matthew Skelton and Manuel Pais’s Team Topologies framework has become the dominant model for organizing around these disciplines. It defines four fundamental team types:
Stream-aligned teams are product or feature teams, focused on delivering business value end to end. They are the primary consumers of the platform.
Platform teams build and maintain the IDP, treating internal developers as their customers. Their success metric is adoption and developer satisfaction, not uptime.
Enabling teams (often where SRE expertise lives) work temporarily alongside stream-aligned teams to help them adopt new practices — observability, SLOs, on-call processes — before stepping back.
Complicated subsystem teams own specific technical domains — ML infrastructure, payment systems, real-time data pipelines — that require deep specialist knowledge.
In practice, most enterprises implement a hybrid. SRE practitioners may be embedded within stream-aligned teams, centralized in a platform team, or organized as an enabling team that sets standards and supports adoption. There is no single right answer — the right structure depends on your scale, your maturity, and your organizational culture.
A key principle: Conway’s Law states that organizations design systems that mirror their own communication structure. If you want loosely coupled, independently deployable microservices, you need loosely coupled, independently operating teams. Team design is architecture.
Tooling Landscape
The ecosystem is large. Below is a practical orientation across the key categories:

The right stack depends on your cloud strategy, existing tooling investments, and team expertise. The goal is not to use the most tools but to use the fewest tools that provide the coverage you need, connected by a coherent observability and automation strategy.
The Role of AI in Modern Operations
AI is reshaping every layer of the DevOps/SRE/Platform Engineering stack, and the productivity gains are no longer theoretical.
In incident response, AI-powered tools can correlate logs, metrics, and traces across thousands of services in seconds — work that previously took senior engineers hours. AI-integrated DevOps teams achieve a 33% reduction in MTTR compared to traditional implementations, and organizations pairing observability platforms with AI incident learning systems see resolution accuracy increase by 35%.
In pipeline optimization, AI models are being used to predict build failures before they occur, recommend test suite optimizations, and identify flaky tests that inflate pipeline times.
In capacity planning, ML models trained on historical traffic patterns enable more accurate autoscaling predictions, reducing both over-provisioning costs and under-provisioning incidents.
In developer experience, AI coding assistants are increasingly integrated into the Golden Path — developers get context-aware help without leaving the standardized toolchain.
The practical implication for engineering leaders: AI doesn’t replace SRE or Platform Engineering — it amplifies both. The organizations that will see the greatest returns are those that invest in the underlying data infrastructure (observability, structured logging, telemetry pipelines) that AI tools need to be effective.
Real-World Case Studies
The best way to understand what modern SRE looks like in practice is to see it in action.
Here are some examples of organizations that moved from reactive, manual operations to resilient, automated reliability — and the results they achieved.
How an Automotive Giant Cut Incident Response Time by 20% A major manufacturer running Airflow and Kubernetes at scale was losing hours to manual log triage every time something broke. By deploying an AI-powered diagnostic agent and centralizing observability through Dynatrace, they cut MTTR by 20% and improved operational efficiency by 20–30% — with the model scaling across additional product teams from there.
How a Media Company Delivered Flawless Live Broadcasts to Millions For a global streaming company, any degradation during a peak broadcast window meant real revenue loss. A multi-layer reliability architecture — combining real-time observability, automated rollback, regional redundancy, and SLO-driven incident response — protected every critical broadcast window with no measurable service degradation.
Common Anti-Patterns to Avoid
DevOps as a job title, not a culture. Hiring a “DevOps engineer” and expecting transformation is the most common mistake. DevOps is a cultural shift that requires organizational change, not an individual contributor role.
SLOs that nobody looks at. Many organizations define SLOs as a compliance exercise, then ignore them. If your SLOs aren’t driving actual release decisions through error budgets, they’re documentation, not engineering tools.
Platform teams that build without customers. Platform Engineering fails when the platform team decides what developers need without talking to developers. Treat internal developer research with the same rigor as external product research.
Observability theater. Deploying monitoring dashboards is not the same as building observability. If your engineers can’t answer “why is this slow?” from your current tooling, you have dashboards, not observability.
Big bang platform migrations. Attempting to migrate all teams to a new platform simultaneously almost always fails. The Golden Path model succeeds precisely because it starts small, validates, and scales incrementally.
Toil as a badge of honor. In organizations without SRE culture, manual on-call work is often rewarded as heroism. SRE reframes this: if you’re repeatedly doing the same manual task, you’ve failed to automate, and that’s an engineering problem to solve.
Build vs. Buy: IDP Decisions
One of the most consequential decisions in a Platform Engineering program is whether to build your Internal Developer Platform from scratch, buy a commercial solution, or adopt an open-source foundation like Backstage and customize it.
Build from scratch gives you maximum flexibility and deep customization but requires significant ongoing investment in platform engineering headcount. It makes sense only for the largest organizations with very specific requirements and the resources to sustain a dedicated platform product team indefinitely.
Buy a commercial IDP (Port, Cortex, OpsLevel, Humanitec) delivers faster time-to-value and lower maintenance overhead. The trade-off is cost, potential lock-in, and the constraints of someone else’s product roadmap. For mid-market enterprises without large platform engineering teams, this is often the pragmatic choice.
Adopt and extend Backstage is the most common enterprise approach. Backstage provides a robust open-source foundation with a large plugin ecosystem. The challenge is that Backstage requires meaningful engineering investment to deploy, customize, and maintain — it is not a turnkey solution. Organizations that succeed with Backstage treat it as a product and staff accordingly.
The right answer depends on your team size, timeline, budget, and how differentiated your internal developer experience needs to be from industry standards.
Conclusion
Platform Engineering, DevOps, and SRE are not competing methodologies, nor are they the exclusive domain of elite technology companies. They are complementary layers of a modern engineering organization — and the combination is now accessible to any enterprise willing to make a structured, phased investment.
For the engineering leader navigating this landscape, the core principle is simple: build a system where doing the right thing is the easiest thing for developers to do. When security is baked into the platform, when deployment is automated and reliable, when incidents are surfaced and resolved through data rather than heroics, the cultural shift follows naturally.
The organizations that will win the next decade of digital competition are not those with the most engineers — they’re those with the most effective engineering systems. This guide is your starting point.
Ready to assess your current DevOps, SRE, and Platform Engineering maturity? Explore Gorilla Logic’s Platform Engineering, DevOps & SRE Solutions →
Related Resources

How a Space Tech Company Moved Satellite Imaging to the Cloud — Without Coming Back to Earth

Zero to SRE: Scaling Observability and Automation Across a Global Automotive Portfolio

Microservices, Massive Savings: How One Computing Giant Cut Costs by 63%