
Kubernetes Container Orchestration
This is post 1 of 3 in the series “Kubernetes Tutorials”
- Kubernetes Container Orchestration
- Build and Deploy a Spring Boot App on Kubernetes (Minikube)
- Kubernetes Tutorial on Rolling Deployments
If you’re reading this article, it’s probably because you already know about or have heard of container orchestration. But if it’s the first time you’ve come across the term, the main point of this article is to show you how to implement amazing, container-based software architecture, so welcome. Check out my second post on how to deploy a Java 8 Spring Boot application on a Kubernetes cluster.
When I started to use container microservices (specifically, using docker containers), I was happy and thought my applications were amazing. As I learned more, though, I understood that when my applications are managing individual containers the container runtime APIs work properly without any trouble, but when managing applications that could have hundreds of containers working across multiple servers or hosts they are inadequate. So my applications weren’t exactly as amazing as I had thought. I needed something to manage the containers, because they needed to be connected to the outside world for tasks such as load balancing, distribution and scheduling. As my applications started to be used by more and more people, my services weren’t able to support a lot of requests; I was nervous because the result of all my effort seemed to be collapsing. But, as you might have already guessed, this is the part of the story where “Kubernetes” comes in.
Kubernetes is an open source orchestrator developed by Google for deploying containerized applications. It provides developers and DevOps with the software they need to build and deploy distributed, scalable, and reliable systems.

Ok, so maybe you are asking yourself, “How could Kubernetes help me?” Personally, Kubernetes helped me with one constant in the life of every application: change. The only applications that do not change are dead ones; as long as an application is alive, new requirements will come in, more code will be shipped, and it will be packaged and deployed. This is the normal lifecycle of all applications, and developers around the world have to take this reality into account when looking for solutions.
If you’re wondering how Kubernetes is structured, let me explain it quickly:
● The smallest unit is the node. A node is a worker machine, a VM or physical machine, depending on the cluster.
● A group of nodes is a cluster.
● A container image wraps an application and its dependencies.
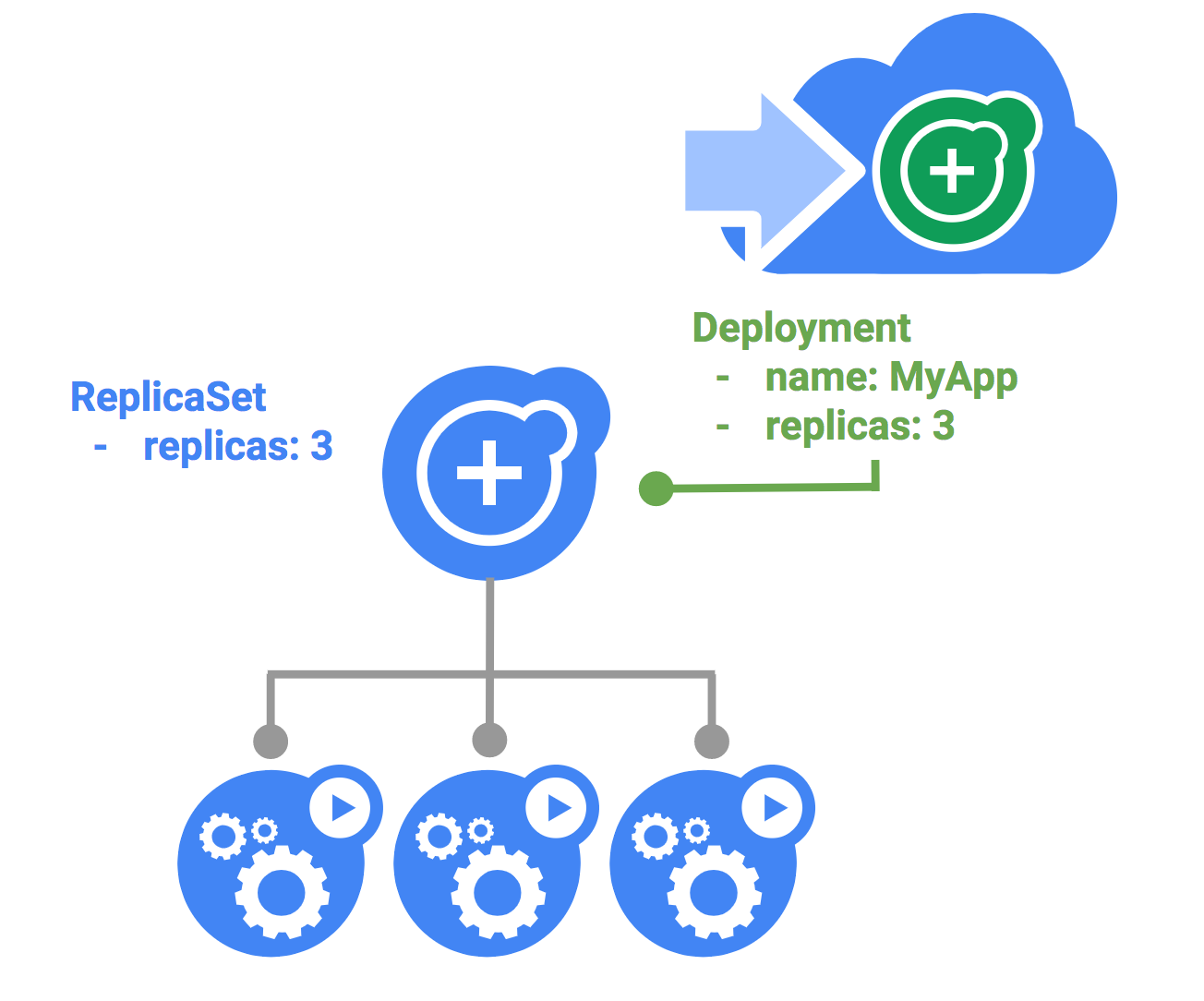
● One or more containers are wrapped into a higher-level structure called a “pod.”
● Pods are usually managed by one more layer of abstraction: deployment.
● A group of pods working as a load balancer to direct traffic to running containers is called “services.”
● A framework responsible for ensuring that a specific number of pod replicas are scheduled and running at any given time is a “replication controller.”
● The key-value tags (i.e. the names) assigned to identify pods, services, and replication controllers are known as “labels.”

When I decided to develop applications that run in multiple operating environments, including dedicated on-prem servers and public clouds such as Azure and AWS, my first obstacle was infrastructure lock-in. Traditionally, applications and the technologies that make them work have been closely tied to the subjacent infrastructure, so it was expensive to use other deployment models despite their potential advantages. This meant that applications tended to become dependent on a particular environment, leading to performance issues. Kubernetes eliminates infrastructure lock-in by offering core capabilities for containers without imposing constraints. It achieves this through a combination of features within the platform itself (pods and services).
My next challenge was to find something to manage my containers. I wanted my applications to be broken down into smaller parts with clear separation of functionality. The abstraction layer provided an individual container image that made me fundamentally rethink how distributed applications are built. This modular focus allows for faster development by smaller teams that are responsible for specific containers. All this sounds good, so far, but this can’t be achieved by containers alone; there needs to be a system for integrating and orchestrating these modular parts. Kubernetes achieves this in part by using pods, or a set of containers that are managed as a single application. The containers exchange resources such as kernel namespaces, IP addresses and file systems. By allowing containers to be placed in this manner, Kubernetes effectively removes the temptation to cram too much functionality into a just one container image.
Another important thing that Kubernetes has offered me is the ability to speed up the process of building, testing, and releasing software with “Kubernetes Controllers.” Thanks to these controllers, I can resolve complicated tasks such as:
● Visibility: I can easily recognize in-process, completed and failed deployments with state querying capabilities.
● Version control: I was able to update deployed pods using newer versions of application images and roll back to an earlier deployment if the current version was not stable.
● Scalability: I was amazed by what Kubernetes can do; applications can be deployed for the first time in a scalable way across pods, and deployments can be scaled in or out at any time.
● Deployment timing: I was able to stop a deployment at any time and resume it later.
As I researched — and played a little bit — with Kubernetes, I found that other orchestration and management tools have emerged such as AWS EC2, Docker Swarm, Apache Mesos and Marathon. Obviously, each one has its benefits, but I have noticed that they are starting to copy each other in functionality and features. Kubernetes, meanwhile, remains hugely popular due to its innovation, big open source community, and architecture.
Without Kubernetes, I would have probably been forced to create my own update workflows, software deployment and scaling; in others words, I would have had to put in a lot more time and effort. Kubernetes enables us to squeeze the maximum utility out containers and set up cloud-native applications that can work anywhere with self-contained, cloud-specific requirements.
Stay tuned for more posts on Kubernetes!

